Multinomial regression
In this tutorial, we will learn how to implement logistic regression using Python. Let us begin with the concept behind multinomial logistic regression. In the binary classification, logistic regression determines the probability of an object to belong to one class among the two classes.
If the predicted probability is greater than 0.5 then it belongs to a class that is represented by 1 else it belongs to the class represented by 0. In multinomial logistic regression, we use the concept of one vs rest classification using binary classification technique of logistic regression.
Now, for example, let us have “K” classes. First, we divide the classes into two parts, “1 “represents the 1st class and “0” represents the rest of the classes, then we apply binary classification in this 2 class and determine the probability of the object to belong in 1st class vs rest of the classes.
Similarly, we apply this technique for the “k” number of classes and return the class with the highest probability. By, this way we determine in which class the object belongs. In this way multinomial logistic regression works. Below there are some diagrammatic representation of one vs rest classification:-
Step 1:-
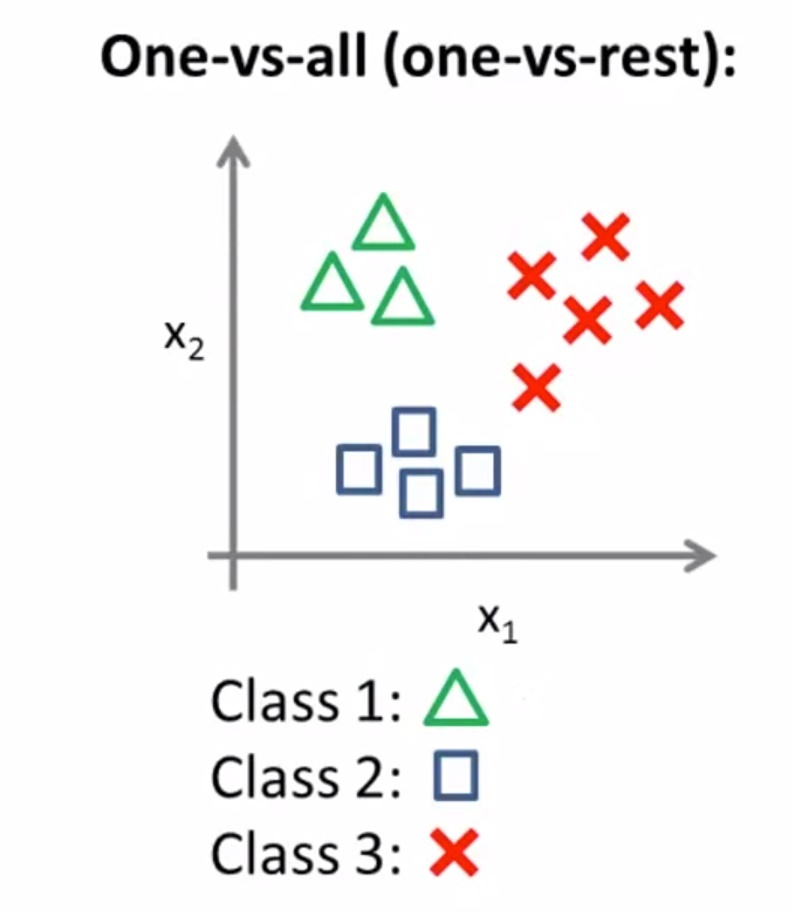
Here there are 3 classes represented by triangles, circles, and squares.
Step 2:
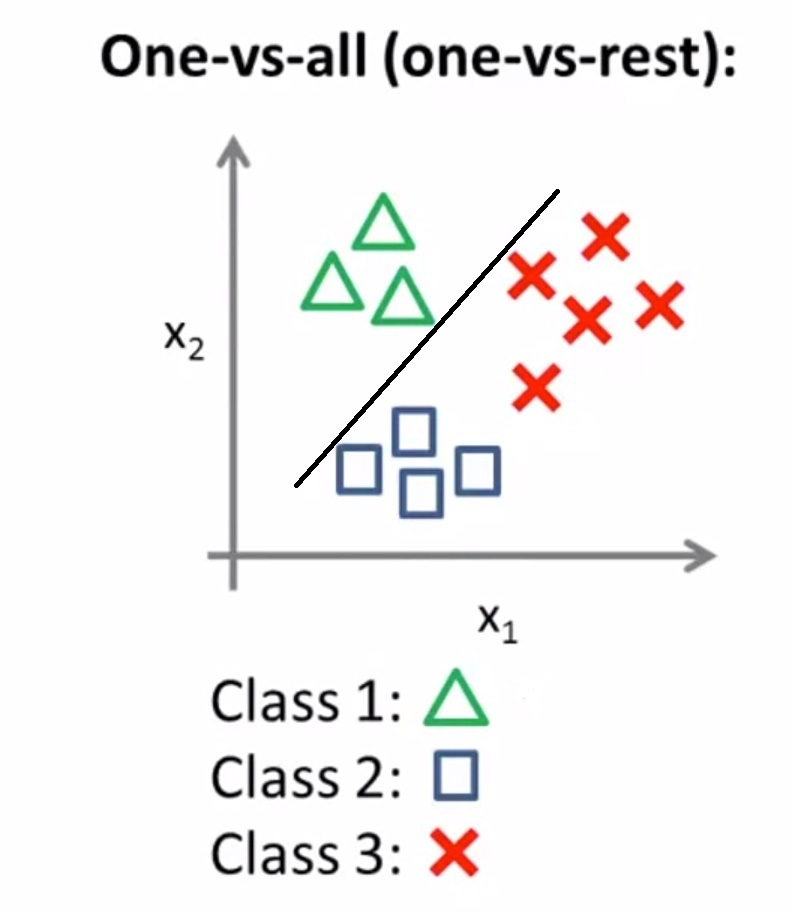
Here we use the one vs rest classification for class 1 and separates class 1 from the rest of the classes.
Step 3:
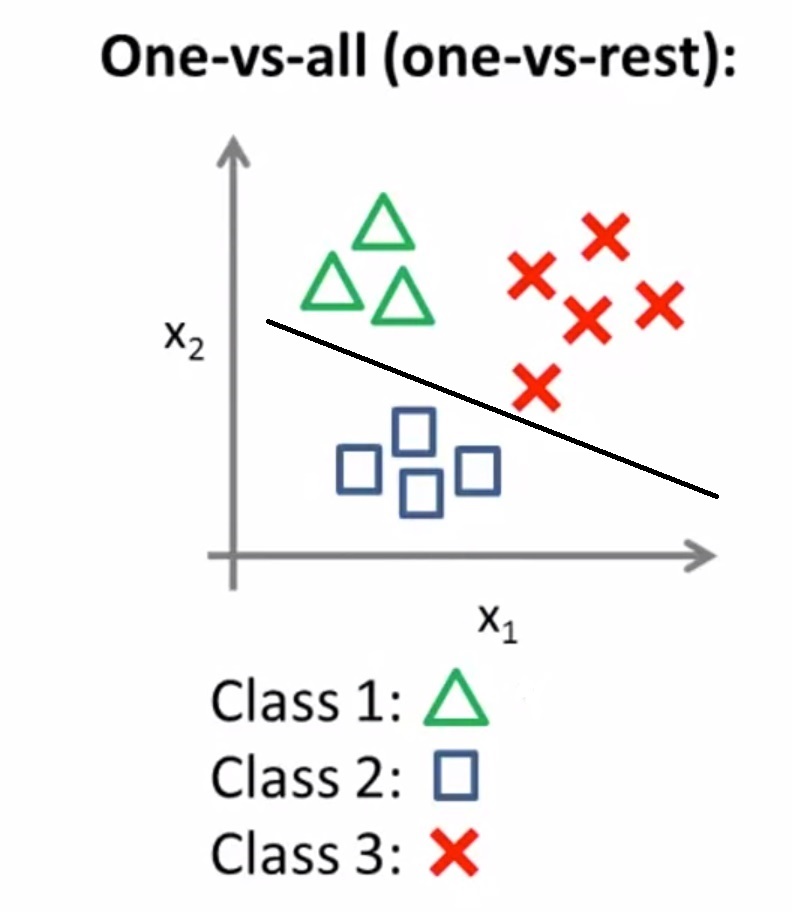
Here we use the one vs rest classification for class 2 and separates class 2 from the rest of the classes.
Step 4:
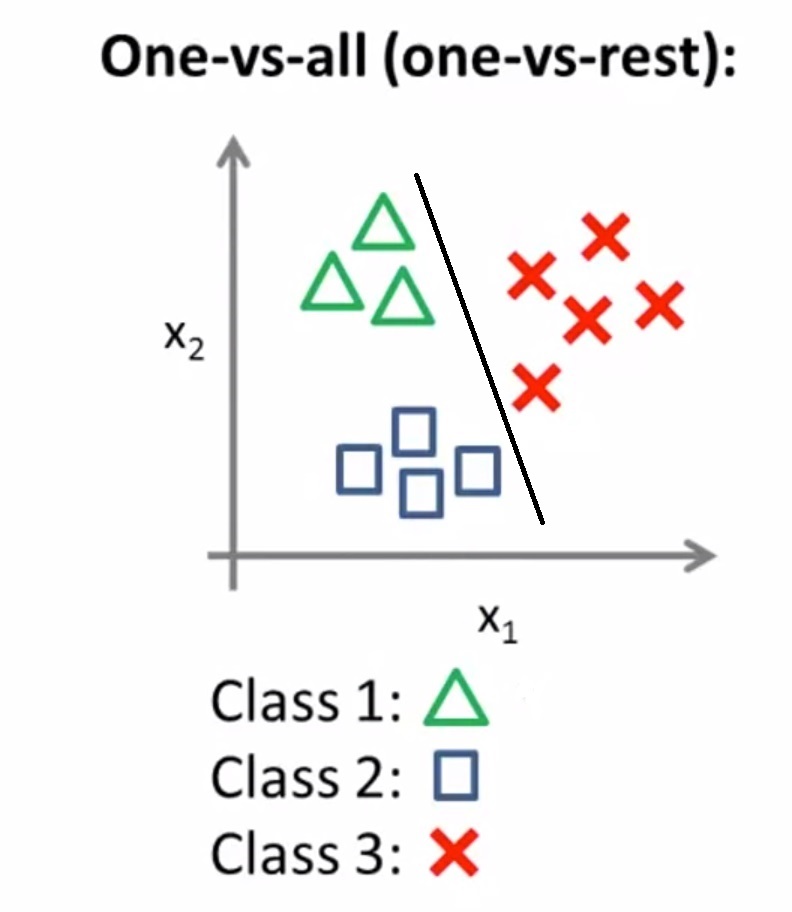
Here we use the one vs rest classification for class 3 and separates class 3 from the rest of the classes.
The implementation of multinomial logistic regression in Python
1> Importing the libraries
Here we import the libraries such as numpy, pandas, matplotlib
2>Importing the dataset
Here we import the dataset named “dataset.csv”
Here we can see that there are 2000 rows and 21 columns in the dataset, we then extract the independent variables in matrix “X” and dependent variables in matrix “y”. The picture of the dataset is given below:-
3> Splitting the dataset into the Training set and Test set
Here we divide the dataset into 2 parts namely “training” and “test”. Here we take 20% entries for test set and 80% entries for training set
4>Feature Scaling
Here we apply feature scaling to scale the independent variables
5>Fitting classifier to the Training set
Here we fit the logistic classifier to the training set
6> Predicting the Test set results
Here we predict the results for test set
7> Making the Confusion Matrix
Here we make the confusion matrix for observing correct and incorrect predictions
Output:-
Confusion matrix:-
Here is the confusion matrix
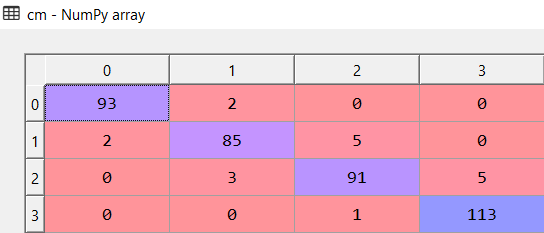
The above pictures represent the confusion matrix from which we can determine the accuracy of our model.
Accuracy:-
Here we calculate the accuracy by adding the correct observations and dividing it by total observations from the confusion matrix
95.5 %
Comments
Post a Comment